数据提取器
数据提取器(Data Extractor)能够从文件中提取稀疏格式的数据,并将其汇集到内部的结构化表格中。收集到的数据可以随时以各种格式(CSV、TSV、HTML、自定义格式)导出。数据提取器可以在几秒钟内分析成千上万个文件,并收集其中的所有原始数据。
它使用简单的指令来识别数据、提取数据,以及将这些数据放置在可供导出的结构化表格中的位置。
它能解析你指定的所有文本文件并进行分析,通过文本标签来理解需要提取什么以及提取到哪里。
数据提取器将杂乱无章的数据转化为井然有序的数据。
所有这些只需一键即可完成。
为什么需要它
- 如果你有大量包含数据的文本文件,并希望将它们迁移到具有字段和记录的结构化数据库中。
- 如果你需要从各种文本文档中,通过不同类型的起始和结束标签或位置来提取可识别的数据。
强大之处
- 数据提取器可以提取手动收集需要数周、数月甚至数年才能完成的数据。
- 它能在几秒钟内为你完成这项工作,它可以扫描数千个文本,分析、复制所需数据,并将其放入你创建的带有所需字段的表格中。
- 它使用各种选项,能够从成千上万个文件中提取数据并以有序的方式保存。
- 它提供所有工具,在一个美观、优雅、仅限Mac的原生应用程序中智能地完成这些特定任务。
- 数据可以导出为各种格式,可直接使用。
易于使用
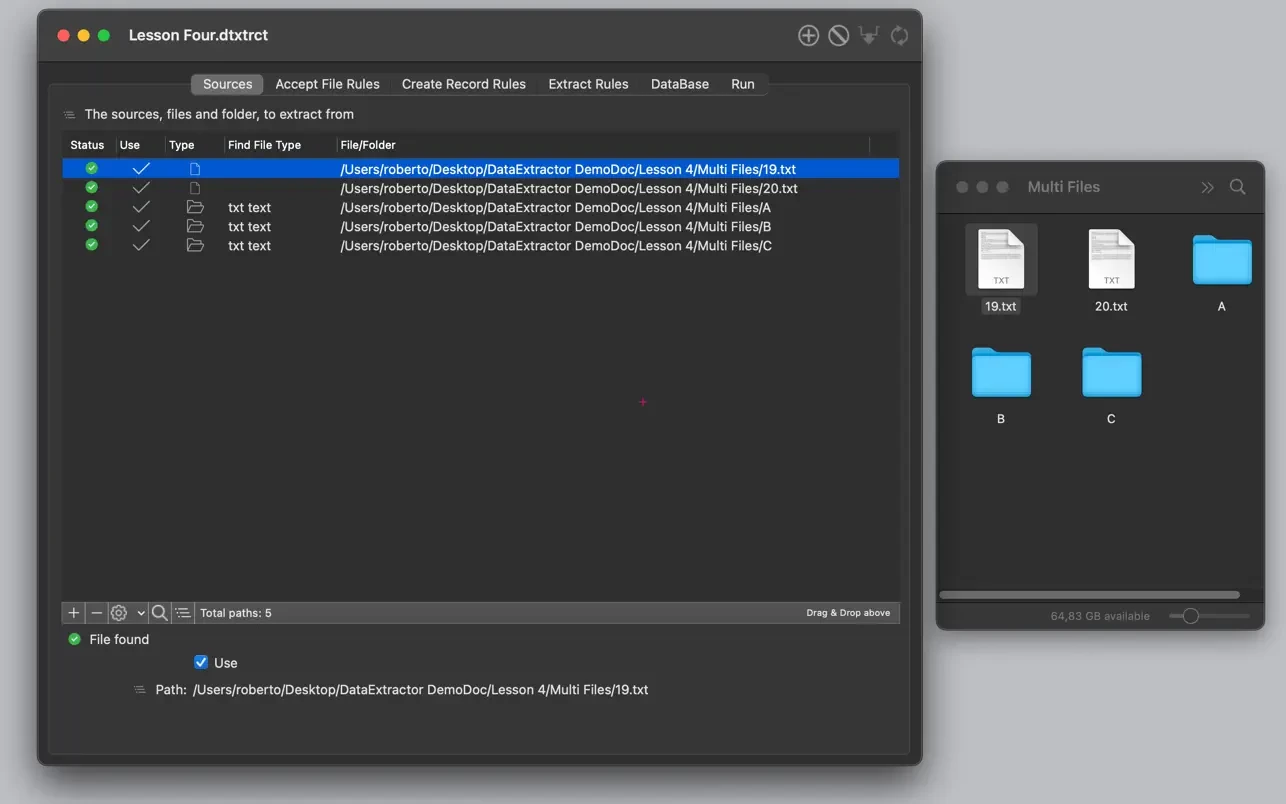
- 在“Sources”(来源)部分,你指定需要解析的文本文件,或需要导航和解析的文件夹。
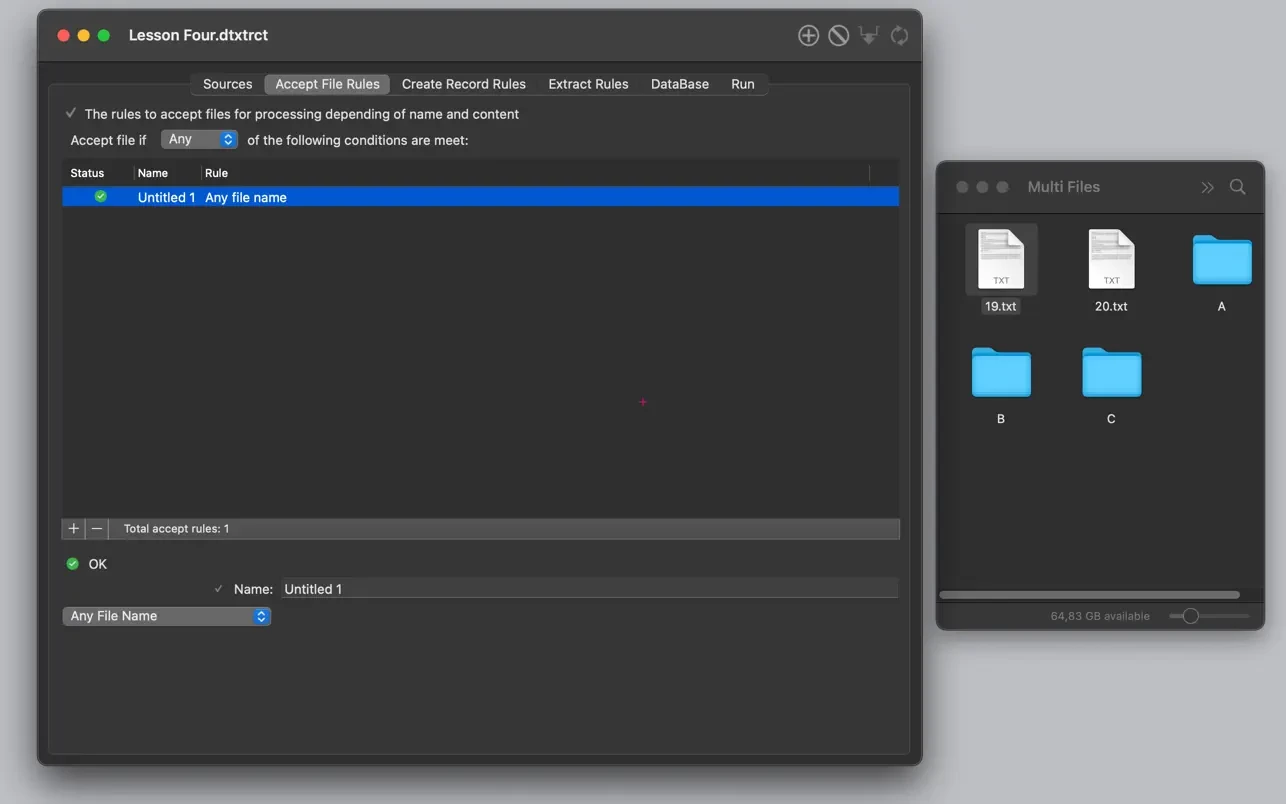
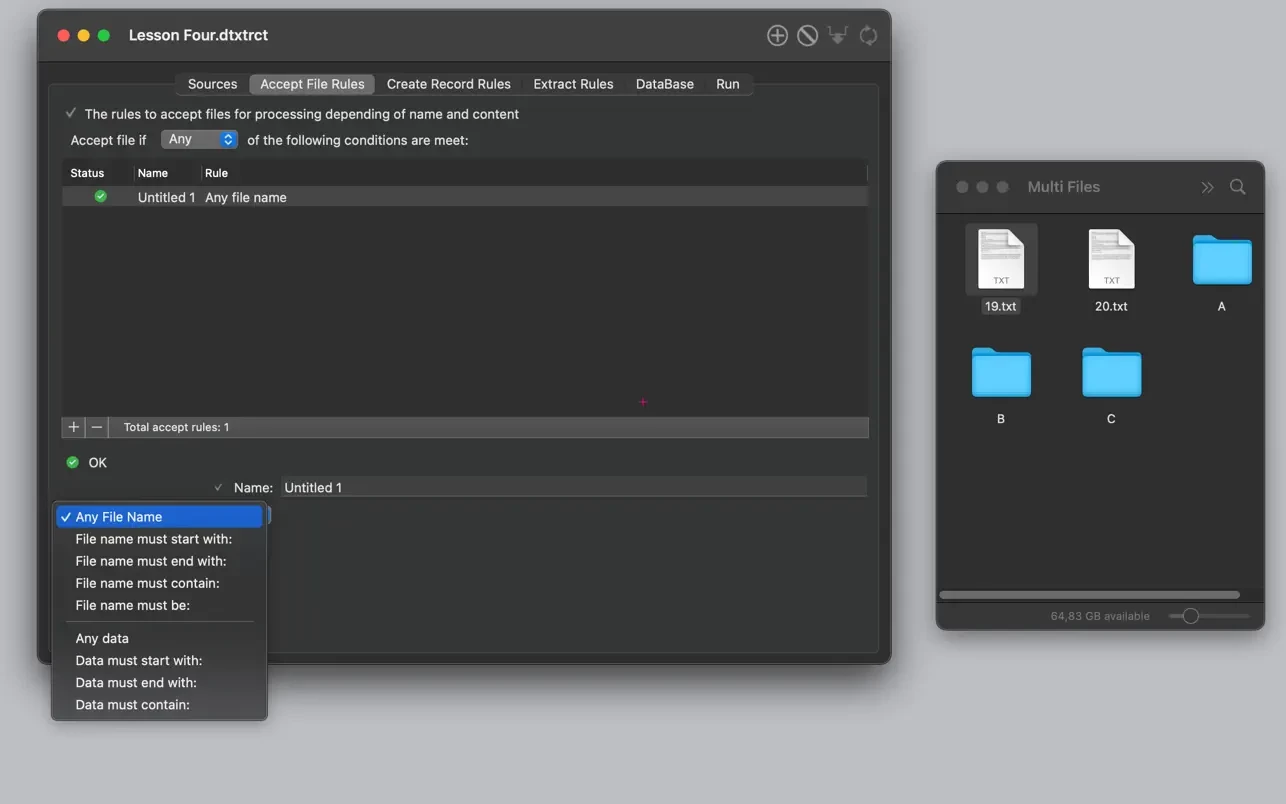
- 在“Accept file rules”(文件接受规则)中,你指定如何接受文件内容进行解析。
- 在“Create Record Rules”(创建记录规则)中,你指定何时在数据目的地插入新记录。
- 在“Extract Rules”(提取规则)中,你指定要提取什么以及将其放置在哪里。
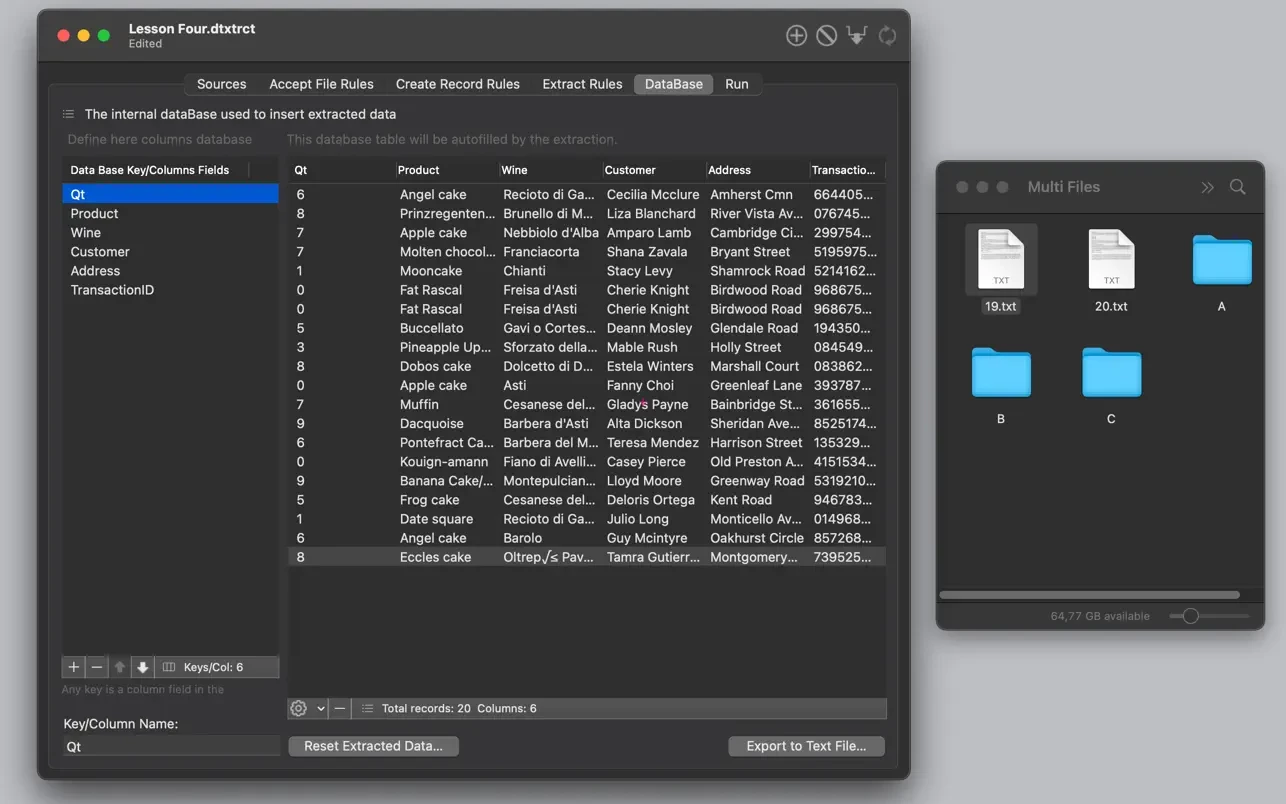
- 在“DataBase”(数据库)中,你指定用于收集数据的表格。
- 在“Run”(运行)中,你可以运行并查看结果摘要。
特点
- 基于文档,每个文档可以使用不同的数据集来源。
- 文档还可以配置为使用特定的提取和目标规则,快速批量处理大量数据。
- 可以将客户订单或任何通过电子邮件接收的数据集转换为数据库记录(数据提取器可以直接分析指向你硬盘上邮箱的电子邮件)。
- 如果服务器输出的订单没有直接插入数据库,它可以收集这些订单。
- 可以通过拖放操作,一次提取一个文件中的数据。
- 与Mail.app接收的邮件配合得很好。
- 可以处理文件夹,提取其中所有文件的数据,包括任何级别的嵌套。
- 如果第一个格式使用可识别的带有标签的模式来识别数据字段,则可以将一种格式的数据转换为另一种格式。
- 可自定义数据列的位置。
- 从文件中提取数据,其中数据记录在一个文件中,记录之间仅由一个可区分的字符串分隔。
- 从文件中提取数据,其中记录由换行符分隔,同一行中的字段仅通过标签进行识别。
- 从具有非唯一、模糊标签的文本文档中提取数据,使用特殊的标签来指示数据提取器真正开始收集数据的位置。
- 仅当文件符合特定特征时才进行解析。
- 仅当数据符合特定特征时才进行提取。
- 即使数据由多个标签指定,也可以提取(它可以将不同的提取内容放入同一个目标字段中)。
- 可以使用“Case Sensitive”(区分大小写)选项处理数据标签。
- 可以在后台运行。
- 始终保持响应,即使是从包含数千个嵌套文件的文件夹中提取数据时。
- 用户可以随时停止该过程。
- 内部数据库表格,完全可自定义,用于收集提取的数据。
- 以各种格式(CSV、TSV、HTML、自定义格式)和不同选项导出数据。
- 包含一个PDF用户手册,其中有4个关于如何使用应用程序的实际教程。
挂载镜像并运行 Open Gatekeeper friendly
在终端窗口中按回车键以绕过 Gatekeeper。
将应用程序拖动到“应用程序”文件夹中。
该应用程序即可使用。
声明:本站资源仅限学习研究使用,请在24小时内删除。建议通过官方渠道购买正版软件,支持开发者创作。

发表评论